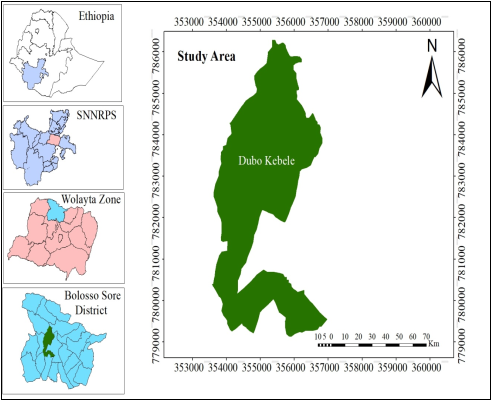
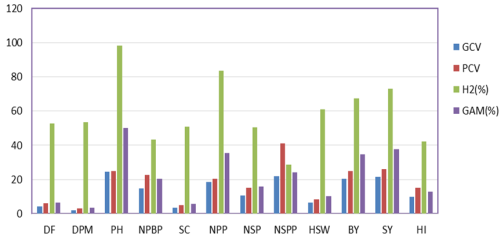
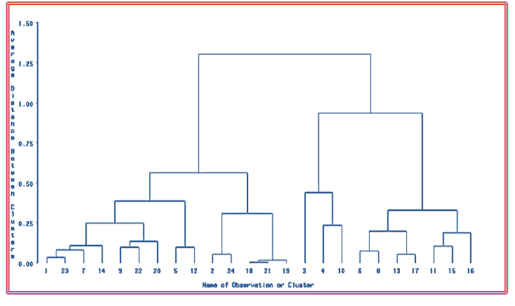
Evaluating genetic variability among genotypes is vital for identifying superior genotypes because selecting parents who create segregating populations is critical in breeding programs. The current study was done at Areka Agricultural Research Center during the 2020/21 major cropping season, with the goal of estimating genetic diversity and character connection among 25 common bean genotypes. The experiment consisted of two replications of a 5 x 5 simple lattice design. Data were obtained on 12 quantitative parameters, and the analysis of variance revealed extremely significant variations between genotypes for all characters. It demonstrated that genotypes vary significantly. GCV and PCV were highest in plant height, number of pods per plant, biological yield, number of seeds per plant, and seed yield, while lowest in days to flowering and days to maturity. Plant height, number of pods per plant, number of seeds per plant, biological yield, and seed yield all showed significant broad-sense heritability (H2) and high predicted genetic advance as a percentage of mean GAM. This suggested the presence of additive gene activity in the inheritance of these traits. The number of major branches per plant, biological yield, days of 50% flowering, hundred seed weight, and harvest index all show a highly substantial and positive link with seed yield at both genotypic and phenotypic levels. The biological yield and harvest index both have a strong positive direct effect on seed output. As indicated, these traits could be utilized for selection to increase seed output. Based on the D2 value, 25 common bean genotypes were divided into four clusters. Clusters I and IV had the greatest inter-cluster distance (766.78), whereas clusters I and II had the smallest (53.78). Breeding programs could use genotypes from distant clusters to increase variety. Thus, the enormous genetic variation among common bean genotypes must be evaluated for use in common bean breeding efforts.
| Published in | American Journal of Plant Biology (Volume 9, Issue 4) |
| DOI | 10.11648/j.ajpb.20240904.16 |
| Page(s) | 135-148 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Common Bean, Correlation, Genetic Advancement, Genetic Variability
Characters | Replication df=(1) | Genotypes df= (24) | Mse | Block/rep df=(8) | Intra block error df=(16) | CV% |
|---|---|---|---|---|---|---|
DF | 1.62 | 10.81** | 2.6 | 2.65 | 3.01 | 4.2 |
DPM | 0.72 | 10.76** | 3.21 | 2.5 | 2.92 | 2.2 |
PH | 0.72 | 301.46** | 2.90 | 2.97 | 2.8 | 3.4 |
NPBP | 0.18 | 1.54** | 0.53 | 0.35 | 0.52 | 17.1 |
SC | 28125 | 154791** | 50563 | 19531 | 505626 | 3.5 |
NPP | 1.62 | 42.90** | 3.62 | 4.24 | 3.5 | 8.4 |
NSP | 0.02 | 1.17** | 0.36 | 0.34 | 0.37 | 10.7 |
NSPP | 224.72 | 1882.80** | 189.40 | 328.62 | 201.4 | 11 |
HSW | 2.29 | 6.61** | 1.76 | 1.32 | 1.54 | 5.2 |
B | 133471 | 1758659** | 270017 | 423965 | 307692 | 14.3 |
SY | 250.25 | 453633** | 66226 | 54186 | 63986 | 13.1 |
HI | 5 | 84.87** | 34.90 | 75.59 | 34.5 | 11.6 |
characters | σ2e | σ2g | σ2p | GCV | PCV | H2(%) | GA | GAM (%) |
|---|---|---|---|---|---|---|---|---|
DF50 | 2.6 | 4.11 | 6.71 | 4.96 | 6.34 | 61.3 | 3.3 | 8 |
DPM | 3.21 | 3.78 | 6.99 | 2.4 | 3.3 | 54.1 | 2.93 | 3.62 |
PH | 2.90 | 149.3 | 152.2 | 24.63 | 26.1 | 98.14 | 24.9 | 50.2 |
NPBP | 0.53 | 0.5 | 1.04 | 16.9 | 24.2 | 50.1 | 1.05 | 24.88 |
SC | 50563 | 52114 | 202677 | 11.16 | 15.66 | 50.75 | 330 | 16.2 |
NPP | 3.62 | 19.64 | 23.25 | 20 | 21.5 | 84.43 | 8.35 | 37.4 |
NSP | 0.36 | 0.41 | 0.77 | 11.23 | 15.4 | 53.3 | 0.97 | 16.9 |
NSPP | 189.40 | 846.7 | 1036.1 | 22.6 | 25 | 81 | 54.2 | 53.7 |
HSW | 1.76 | 2.43 | 4.19 | 6.35 | 8.6 | 58 | 2.45 | 10.24 |
BY | 270017 | 744321 | 1014338 | 22.23 | 25.95 | 73.4 | 1522.4 | 39.2 |
SY | 66226 | 193703.5 | 259929.5 | 22.34 | 24.87 | 74.5 | 782.4 | 39.72 |
HI | 34.90 | 25.1 | 59.6 | 10.1 | 15.3 | 42.2 | 6.65 | 13.18 |
No of cluster | No of genotypes | Genotypes clustered |
|---|---|---|
I | 5 | MALB-89, MALB-135, MALB-173, MALB-131, MALB-106, |
II | 10 | MALB-172, MALB-176, MALB-125, Hawassa dume, MALB-175, MALB-53, MALB-105, MALB-113, MALB-155, MALB-167 |
III | 7 | MALB-168, MALB-122, MALB-82, MALB-44, MALB-17, MALB-157, MALB-132, |
IV | 3 | MALB-104, MALB-90, MALB-115, |
Cluster | I | II | III | IV |
|---|---|---|---|---|
I | 3.21 | 53.78** | 262.11** | 766.78** |
II | 1.83 | 84.87** | 430.95** | |
III | 2.54 | 142.63** | ||
IV | 4.24 |
Characters | I | II | III | IV |
|---|---|---|---|---|
DF | 39.83 | 41.55 | 40.71 | 40.3 |
DM | 80.5 | 82 | 79.3 | 80.5 |
PH | 37.2 | 51.2 | 54.92 | 52.5 |
NPBP | 3.6 | 4.25 | 4.57 | 4.3 |
SC | 194000 | 200500 | 210357 | 222083 |
NPP | 16.9 | 18.25 | 21 | 19.83 |
NSPP | 83.8 | 90.4 | 93 | 97 |
NSP | 5 | 5.2 | 5.4 | 6 |
HSW | 21.67 | 24.015 | 25 | 24.3 |
BY | 3675 | 3837.5 | 4038.7 | 4007 |
SY | 1659.17 | 1977.08 | 2032.8 | 1997 |
HI | 45.19 | 51.52 | 50.3 | 49.84 |
DF50 | DPM | PH | NPBP | SC | NPP | NSP | NSPP | HSW | BY | SY | HI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
DF50 | 1 | 0.758** | 0.346NS | 0.494* | -0.14NS | 0.355* | 0.080NS | 0.401* | 0.356* | 0.443* | 0.57** | 0.369* |
DPM | 0.724** | 1 | 0.360NS | 0.428* | -0.12NS | 0.25N | 0.088NS | 0.383* | 0.29NS | 0.33NS | 0.413* | 0.387* |
PH | 0.319* | 0.328* | 1 | 0.478* | 0.330NS | 0.83** | -0.19NS | 0.649** | 0.870** | 0.403* | 0.448* | 0.19NS |
NPBP | 0.419** | 0.426** | 0.447** | 1 | 0.240NS | 0.59** | -0.16NS | 0.481** | 0.603** | 0.702** | 0.89** | 0.649** |
SC | -0.06NS | -0.03NS | 0.299* | 0.260* | 1 | 0.503* | 0.374* | 0.596** | 0.568** | 0.23NS | 0.14NS | 0.376* |
NPP | 0.257* | 0.202NS | 0.803** | 0.574** | 0.394** | 1 | -0.23NS | 0.732** | 0.905** | 0.442* | 0.492* | 0.27NS |
NSP | 0.035NS | 0.005NS | -0.17NS | -0.11NS | 0.297* | -0.2NS | 1 | 0.445* | -0.2NS | -0.28NS | -0.2NS | 0.33NS |
NSPP | 0.313* | 0.254* | 0.625** | 0.440** | 0.502** | 0.74** | 0.465** | 1 | 0.708** | 0.24NS | 0.397* | 0.504* |
HSW | 0.233NS | 0.259* | 0.798** | 0.608** | 0.392** | 0.85** | -0.08NS | 0.649** | 1 | 0.426* | 0.53** | 0.35NS |
BY | 0.364** | 0.257* | 0.369** | 0.622** | 0.043NS | 0.423* | -0.18NS | 0.24NS | 0.410** | 1 | 0.87** | 0.10NS |
SY | 0.457** | 0.369** | 0.432** | 0.851** | 0.179NS | 0.49** | -0.02NS | 0.379** | 0.511** | 0.825** | 1 | 0.566** |
HI | 0.255* | 0.279* | 0.197NS | 0.551** | 0.346** | 0.259* | 0.223NS | 0.378** | 0.325* | -0.05NS | 0.51** | 1 |
DF50 | DPM | PH | NPBP | NSPP | NPP | HSW | BY | HI | gr | |
|---|---|---|---|---|---|---|---|---|---|---|
DF50 | 0.0127 | 0.0299 | -0.036 | 0.0377 | 0.0008 | 0.0016 | -0.014 | 0.3428 | 0.156 | 0.57** |
DPM | 0.0106 | 0.0358 | -0.013 | 0.0332 | -0.009 | 0.0011 | -0.002 | 0.2615 | 0.163 | 0.413* |
PH | 0.0051 | 0.0127 | -0.038 | 0.0327 | 0.0096 | 0.0039 | -0.008 | 0.3118 | 0.079 | 0.448* |
NPBP | 0.0069 | 0.0173 | -0.018 | 0.0686 | 0.0094 | 0.0028 | -0.006 | 0.5432 | 0.274 | 0.89** |
NSPP | 0.0004 | -0.002 | -0.015 | 0.0276 | 0.0234 | 0.0024 | -0.006 | 0.1833 | 0.159 | 0.39* |
NPP | 0.0045 | 0.0090 | -0.030 | 0.0402 | 0.0117 | 0.0047 | -0.01 | 0.3420 | 0.104 | 0.49* |
HSW | 0.0044 | 0.0104 | -0.032 | 0.0413 | 0.0132 | 0.0043 | -0.01 | 0.329 | 0.148 | 0.53** |
BY | 0.005 | 0.0120 | 0.0151 | 0.048157 | 0.0055 | 0.0021 | -0.042 | 0.7738 | 0.0439 | 0.87** |
HI | 0.004687 | 0.013847 | -0.007 | 0.044521 | 0.008792 | 0.001174 | -0.00345 | 0.080477 | 0.4230 | O0.566** |
DF50 | DPM | PH | NPBP | NSPP | NPP | HSW | BY | HI | pr | |
|---|---|---|---|---|---|---|---|---|---|---|
DF50 | 0.046765 | -0.03139 | -0.00269 | 0.021602 | -0.00016 | -0.00345 | -0.00253 | 0.263934 | 0.177912 | 0.457** |
DPM | 0.036103 | -0.04066 | -0.00231 | 0.020927 | 0.00015 | -0.00226 | -0.00258 | 0.235423 | 0.1875 | 0.369** |
PH | 0.017209 | -0.01285 | -0.00731 | 0.020117 | -0.00068 | -0.00876 | -0.00695 | 0.300592 | 0.091619 | 0.432** |
NPBP | 0.022447 | -0.01891 | 0.00327 | 0.045004 | -0.00089 | -0.00626 | 0.00529 | 0.506689 | 0.309481 | 0.851** |
NSPP | 0.003554 | 0.00281 | 0.0023 | 0.018767 | -0.00214 | 0.00502 | 0.00456 | 0.204468 | 0.180043 | 0.379** |
NPP | 0.014778 | -0.00842 | -0.00587 | 0.025832 | 0.00099 | -0.0109 | -0.00745 | 0.344581 | 0.129439 | 0.49** |
HSW | 0.013562 | -0.01204 | 0.00583 | 0.027363 | -0.00112 | 0.00933 | -0.00871 | 0.333991 | 0.173118 | 0.511** |
BY | 0.015152 | 0.01175 | -0.0027 | 0.027993 | 0.00054 | -0.00461 | 0.00357 | 0.814612 | -0.00959 | 0.825** |
HI | 0.015619 | -0.01431 | -0.00126 | 0.026147 | -0.00072 | -0.00265 | -0.00283 | -0.01466 | 0.53267 | 0.51** |
AARC | Areka Agricultural Research Center |
ATA | Agricultural Transformation Agency |
CIAT | Centro International de Agriculture Tropical |
CSA | Central Statistic's Agency |
ETB | Ethiopian Birr |
GDP | Gross Domestic Production |
SARI | Southern Agricultural Research Institute |
SNNPR | Southern Nation, Nationalities and Peoples Region |
| [1] | Ahmed Shahid and Kamaluddin, C. (2013). “Correlation and path analysis for agro- morphological traits in Rajmash bean under Baramulla Kashmir,” African Journal of Agricultural Research, vol. 8, no. 18, pp. 2027–2032. |
| [2] | Aklade, S. A., Patil, H. E. Sarkar, M. and Patel B. K. (2018). Genetic Variability, Correlation and Path Analysis for Yield and Yield Related Traits in Vegetable Type French Bean (Phaseolus vulgaris L.), Int. J. Pure App. Biosci. 6: 25-32. |
| [3] | Allard R. W., (1960). Principles of Plant Breeding. John Wiley and Sons. Inc. New York pp. 99-108. |
| [4] | Amanuel Abebe Girma Alemayehu, (2018). Production Status, Adoption of Improved Common Bean (Phaseolus vulgaris L.) Varieties and Associated Agronomic Practices in Ethiopia. J Plant Sci Res. 2018; 5(1): 178. |
| [5] | Awol Mohammed, Bulti Tesso, Chris Ojiewo, and Seid Ahmed. 2019. Assessment of genetic variability and heritability of agronomic traits in Ethiopian chickpea (cicer arietinum L) landraces. Black Sea Journal of Agriculture. 2: 10-15. |
| [6] | Aziza Ahmed (2019). Genetic variability and trait associations of common bean (phaseolus vulgaris l.) genotypes in sirinka northeastern amhara. MSC thesis. |
| [7] | Beebe, S., Rao I., Blair M. and Acosta J. (2013). Phenotyping common beans for adaptation to drought. Frontiers Physiology. 4: 1-20. |
| [8] | Berecha Gutu. (2015). Genetic variability and path coefficient analysis for yield and yield related traits in common bean (Phaseolus vulgaris L.). M. S. C Thesis, Haramaya University. |
| [9] | Burton, W. and H. Devane (1953). “Estimating heritability in tall Fescue (Festucaarundinacea) from replicated clonal materials,” Agronomy Journal, vol. 45, pp. 487–488. |
| [10] | Cochran, W. G., and Cox, M. (1957). Experimental designs. John Wiley and Sons, Inc, New York 611 p. |
| [11] | CSA (Central Statistics Agency of Ethiopia) (2015). Report on area and crop production of major crops for 2015 Meher season, 111p. |
| [12] | Demelash Bassa. (2018). Common Bean Improvement Status (Phaseolus vulgaris L.) in Ethiopia. Adv. Crop. Sci. Tech. 6: 347. Descriptors. Crop Breeding and Applied Biotechnology, 12: 76-84. |
| [13] | Deway D. R., and Lu K., H. (1959). A correlation and path coefficient analysis of components of crested wheat grass seed production. Agron. J. 51: 515-518. |
| [14] | Falconer D, Mackay F (1996). Introduction to Quantitative Genetics 4th ed. Longman Group Limited Malaysia P 438. |
| [15] | Ghimire H. and Mandal N. H. (2019). Genetic variability, heritability and genetic advance of common bean (Phaseolus vulgaris L.) Genotypes at mountain environment of Nepal. 6: 10 -2019. |
| [16] | Johnson HW, Robinson HF, Comstock RE (1955). Estimates of genetic and environmental variability in soybeans. Agronomy Journal 47: 314-318. |
| [17] | Kedir shafi ahmed (2019). enetic variability and association of yield and yield related traits in common bean (phaseolus vulgaris l.) accessions in eastern Ethiopia MSC thesis. Haramaya University. |
| [18] | Lad D. B., Longmei N. and Borle U. M. (2017). Studies on Genetic Variability, Association of Characters and Path Analysis in French bean (Phaseolus vulgaris L.). Int. J. Pure. Appl Biosci. 5(6): 1065–1069. |
| [19] | Legesse Dadi. (2015). Genetic Variability and Association of Characters for Yield and Yield Components in Some Field pea (Pisum sativum L.). M. Sc Thesis, Haramaya University, Ethiopia, 139pp. |
| [20] | Lima, M. S. Carneiro, J. E. S. Carneiro, P. C. S. Pereira, C. S. Vieira, R. F. Cecon, P. R. (2012). M., editor. New York, NY; Dordrecht; Heidelberg; London: Springer, 1–36. |
| [21] | Mamidi, S., Rossi, M., Moghaddam, S. M., Annam, D., Lee, R., Papa, R. (2013). Demographic Factors shaped diversity in the two gene pools of wild common bean (Phaseolus vulgaris L.) heredity 110, 267–276. |
| [22] | Meena B. L., Das S. P., Meena S. K., Kumari R., Devi A. G. and Devi H. L. (2017). Assessment of GCV, PCV, heritability and genetic advance for yield and its components in field pea (PisumsativumL.). International Journal of Current Microbiology and Applied Sciences. 6: 1025-1033. |
| [23] | Mulugeta Atnaf, Hussein Mohammed and Habtamu Zeleke. (2013). Inheritance of Primary yield component traits of common beans (Phaseolus vulgaris L.): Number of Seeds per Pod and 1000 Seeds Weight in an 8X8 Diallel Cross Population. International Journal of Biology Food Vet. Agric. Eng. 7(1): 1-5. |
| [24] | Perera U. I. P., Chandika K. K. J., and Disna Ratnasekera. (2017). Genetic variation, traits association and evaluation of mung bean genotypes for agronomic and yield components. Journal of the National Science Foundation of Sri Lanka. 45: 347-353. |
| [25] | Prajapati KN, Patel MA, Patel JR, Joshi NR, Patel AD, Patel JR (2014). Genetic Variability, Character Association and Path Coefficient analysis in Turmeric (Curcuma longa L.). Electronic Journal of Plant Breeding 5(1): 131-137. |
| [26] | Raily R, Chowdhry A (2003). Estimation of variation and heritability of some physiomorphic traits of wheat under drought condition. AsianJournal of Plant Science 2(10): 748-755. Readings. 4th Edn, Prentice-Hall, Englewood Cliffs, NJ, 1543pp red bean marketing in halaba special district, Ethiopia, M. Sc. Thesis, University of Relationship between yield and its component characters of bush bean (Phaseolusl.)’. |
| [27] | Sadeghi, K. Cheghumirza, and R. Dorri, (2011). “The study of morphoagronomic trait relationship in common bean (Phaseolus vulgaris L.),” Biharean Biologist, vol. 5, no. 2, pp. 102–108. |
| [28] | Sengupta K, Kataria AS (1971). Path coefficient analysis for some characters in soybean. Indian J. Genet. 31: 290-295. |
| [29] | Singh P., (2001). “Broadening the genetic base of common beans cultivars: a review,” Crop Science, vol. 41, pp. 1659–1675. |
| [30] | Temesgen Kedir (2020). Genetic variability and association of traits in indeterminate common bean (phaseolus vulgaris l.) genotypes in finoteselam, west gojam, Ethiopia. MSC thesis Bahir Dar University. |
| [31] | Weber R. and R. Moorthy, (1952). “Heritable and nonheritable relationship and variability of oil content and agronomic characters in the F2 generations of soybean crosses,” AgronomyJournal, vol. 44, pp. 202–209. |
| [32] | Wondwosen, W. and Abebe, B. (2017). Genetic variability, heritability and genetic advance of some common bean (Phaseolus vulgaris L.) varieties at Bench-Maji Zone, Southwest Ethiopia. Asian J. Crop Sci. 9: 133-140. |
| [33] | Yitayal Abebe and Lema Zemedu. (2019). Common Bean Production, Marketing, and Validation of New Product Concepts. Research Report No 125. |
| [34] | Yonas Moges, (2017). Genetic diversity in speckled bean (Phaseolus vulgaris L.) genotypes in Ethiopia. Journal of Plant Breeding and Crop Science. 9: 200-207. |
| [35] | Zelalem Zewdu (2014). Evaluatio n of agronomic traits of different common bean (Phaseolus Vulgaris L.) lines in Metekel zone, North Western part of Ethiopia. Wudpecker Journal of Agricultural Research 3(1): 39–43. |
APA Style
Kuma, A. K. (2024). Genetic Variability and Character Association among Common Bean (Phaseolus vulgaris L.) Genotypes at Areka, Southern Ethiopia. American Journal of Plant Biology, 9(4), 135-148. https://doi.org/10.11648/j.ajpb.20240904.16
ACS Style
Kuma, A. K. Genetic Variability and Character Association among Common Bean (Phaseolus vulgaris L.) Genotypes at Areka, Southern Ethiopia. Am. J. Plant Biol. 2024, 9(4), 135-148. doi: 10.11648/j.ajpb.20240904.16
AMA Style
Kuma AK. Genetic Variability and Character Association among Common Bean (Phaseolus vulgaris L.) Genotypes at Areka, Southern Ethiopia. Am J Plant Biol. 2024;9(4):135-148. doi: 10.11648/j.ajpb.20240904.16
@article{10.11648/j.ajpb.20240904.16,
author = {Amanuel Kutafo Kuma},
title = {Genetic Variability and Character Association among Common Bean (Phaseolus vulgaris L.) Genotypes at Areka, Southern Ethiopia
},
journal = {American Journal of Plant Biology},
volume = {9},
number = {4},
pages = {135-148},
doi = {10.11648/j.ajpb.20240904.16},
url = {https://doi.org/10.11648/j.ajpb.20240904.16},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajpb.20240904.16},
abstract = {Evaluating genetic variability among genotypes is vital for identifying superior genotypes because selecting parents who create segregating populations is critical in breeding programs. The current study was done at Areka Agricultural Research Center during the 2020/21 major cropping season, with the goal of estimating genetic diversity and character connection among 25 common bean genotypes. The experiment consisted of two replications of a 5 x 5 simple lattice design. Data were obtained on 12 quantitative parameters, and the analysis of variance revealed extremely significant variations between genotypes for all characters. It demonstrated that genotypes vary significantly. GCV and PCV were highest in plant height, number of pods per plant, biological yield, number of seeds per plant, and seed yield, while lowest in days to flowering and days to maturity. Plant height, number of pods per plant, number of seeds per plant, biological yield, and seed yield all showed significant broad-sense heritability (H2) and high predicted genetic advance as a percentage of mean GAM. This suggested the presence of additive gene activity in the inheritance of these traits. The number of major branches per plant, biological yield, days of 50% flowering, hundred seed weight, and harvest index all show a highly substantial and positive link with seed yield at both genotypic and phenotypic levels. The biological yield and harvest index both have a strong positive direct effect on seed output. As indicated, these traits could be utilized for selection to increase seed output. Based on the D2 value, 25 common bean genotypes were divided into four clusters. Clusters I and IV had the greatest inter-cluster distance (766.78), whereas clusters I and II had the smallest (53.78). Breeding programs could use genotypes from distant clusters to increase variety. Thus, the enormous genetic variation among common bean genotypes must be evaluated for use in common bean breeding efforts.
},
year = {2024}
}
TY - JOUR T1 - Genetic Variability and Character Association among Common Bean (Phaseolus vulgaris L.) Genotypes at Areka, Southern Ethiopia AU - Amanuel Kutafo Kuma Y1 - 2024/12/12 PY - 2024 N1 - https://doi.org/10.11648/j.ajpb.20240904.16 DO - 10.11648/j.ajpb.20240904.16 T2 - American Journal of Plant Biology JF - American Journal of Plant Biology JO - American Journal of Plant Biology SP - 135 EP - 148 PB - Science Publishing Group SN - 2578-8337 UR - https://doi.org/10.11648/j.ajpb.20240904.16 AB - Evaluating genetic variability among genotypes is vital for identifying superior genotypes because selecting parents who create segregating populations is critical in breeding programs. The current study was done at Areka Agricultural Research Center during the 2020/21 major cropping season, with the goal of estimating genetic diversity and character connection among 25 common bean genotypes. The experiment consisted of two replications of a 5 x 5 simple lattice design. Data were obtained on 12 quantitative parameters, and the analysis of variance revealed extremely significant variations between genotypes for all characters. It demonstrated that genotypes vary significantly. GCV and PCV were highest in plant height, number of pods per plant, biological yield, number of seeds per plant, and seed yield, while lowest in days to flowering and days to maturity. Plant height, number of pods per plant, number of seeds per plant, biological yield, and seed yield all showed significant broad-sense heritability (H2) and high predicted genetic advance as a percentage of mean GAM. This suggested the presence of additive gene activity in the inheritance of these traits. The number of major branches per plant, biological yield, days of 50% flowering, hundred seed weight, and harvest index all show a highly substantial and positive link with seed yield at both genotypic and phenotypic levels. The biological yield and harvest index both have a strong positive direct effect on seed output. As indicated, these traits could be utilized for selection to increase seed output. Based on the D2 value, 25 common bean genotypes were divided into four clusters. Clusters I and IV had the greatest inter-cluster distance (766.78), whereas clusters I and II had the smallest (53.78). Breeding programs could use genotypes from distant clusters to increase variety. Thus, the enormous genetic variation among common bean genotypes must be evaluated for use in common bean breeding efforts. VL - 9 IS - 4 ER -
Department of Plant Science, Dilla University, Dilla, Ethiopia
Information