Breast cancer is a disease that affects the majority of women and it is the second most common cause of death among women globally. Medical scientists have proven that there are a vast number of genes that are responsible for breast cancer. Among them, all genes are not equally responsible. Therefore, the most relevant and informative genes are needed to find out to control the disease. The objectives of our study are: (i) To find the most informative and significant genes using different statistical test-based feature selection techniques (FST) as well as find the best classifier and (ii) To validate our experimental results using a simulated dataset. The breast cancer dataset is a benchmark dataset provided by Kent Ridge Biomedical Data Repository, USA. In our study, we have used different statistical test-based feature selection techniques such as the t-test and Wilcoxon signed rank sum (WCSRS) test. Naïve Bayes (NB), Adaboost (AB), linear discriminant analysis (LDA), artificial neural network (ANN), k-nearest neighbor (KNN), and random forest (RF) are treated as classification techniques. Our analysis included 24,188 genes and 97 patients. Among them, 46 patients were with cancer and 51 were in control. We considered 70% of the dataset as a training set and the rest is a test set and repeated this procedure about 1000 times. Among all the combinations of FST and classification techniques t-test-based Naive Bayes classifier gives us the highest classification accuracy. The analysis of our study indicates that the integration of t-test-based FST and Naïve Bayes classifier produces the maximum classification accuracy.
| Published in | Machine Learning Research (Volume 10, Issue 2) |
| DOI | 10.11648/j.mlr.20251002.13 |
| Page(s) | 124-130 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Breast Cancer, Feature Selection, Machine Learning, Classification
Genes | Gene 1 | Gene 2 | ….…….. | Gene 24,481 |
|---|---|---|---|---|
Sample 1 | ||||
Sample 2 | ||||
….…….. | ||||
Sample 97 |
Tests | P-value | Genes | Measure | AB | ANN | KNN | LDA | RF | NB* |
|---|---|---|---|---|---|---|---|---|---|
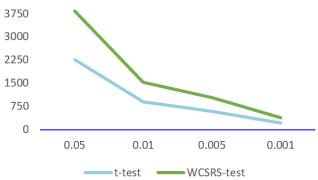
t-test | 0.05 | 2265 | ACC | 81.00 | 81.84 | 82.57 | 86.21 | 86.79 | 87.96 |
AUC | 86.00 | 86.05 | 87.35 | 88.26 | 88.66 | 91.18 | |||
0.01 | 902 | ACC | 79.98 | 80.00 | 82.76 | 84.83 | 85.00 | 85.26 | |
AUC | 82.56 | 83.59 | 85.22 | 86.27 | 88.68 | 89.42 | |||
0.005 | 587 | ACC | 78.76 | 79.62 | 81.00 | 82.76 | 84.62 | 85.97 | |
AUC | 82.21 | 82.80 | 86.14 | 86.38 | 87.24 | 88.87 | |||
0.001 | 218 | ACC | 45.65 | 78.03 | 80.09 | 82.07 | 82.00 | 83.59 | |
AUC | 81.00 | 81.57 | 85.32 | 84.84 | 85.94 | 86.88 | |||
WCSRS test | 0.05 | 3829 | ACC | 81.02 | 81.03 | 82.41 | 84.66 | 84.75 | 85.31 |
AUC | 80.45 | 80.76 | 83.78 | 80.65 | 82.19 | 86.33 | |||
0.01 | 1530 | ACC | 80.11 | 80.31 | 81.93 | 81.97 | 82.09 | 84.45 | |
AUC | 81.87 | 82.59 | 86.00 | 86.08 | 86.66 | 86.72 | |||
0.005 | 1030 | ACC | 79.56 | 79.38 | 80.59 | 82.93 | 82.97 | 83.55 | |
AUC | 80.74 | 81.31 | 82.30 | 84.17 | 84.51 | 85.65 | |||
0.001 | 381 | ACC | 71.98 | 72.07 | 77.59 | 78.65 | 78.72 | 80.91 | |
AUC | 79.89 | 80.93 | 81.92 | 82.97 | 83.00 | 84.31 |
Tests | P-value | Genes | Measure | AB | ANN | KNN | LDA | RF | NB |
|---|---|---|---|---|---|---|---|---|---|
t-test | 0.05 | 351 | ACC | 80.21 | 80.47 | 82.15 | 82.58 | 83.52 | 84.21 |
AUC | 86.78 | 88.37 | 89.14 | 89.62 | 90.41 | 94.64 | |||
0.01 | 65 | ACC | 79.08 | 80.89 | 81.28 | 82.05 | 82.55 | 83.94 | |
AUC | 85.45 | 86.15 | 88.23 | 88.75 | 90.91 | 92.27 | |||
0.005 | 30 | ACC | 71.98 | 72.89 | 76.11 | 78.22 | 79.39 | 80.17 | |
AUC | 81.97 | 86.39 | 88.07 | 88.77 | 89.39 | 89.90 | |||
WCSRS test | 0.05 | 337 | ACC | 76.56 | 78.84 | 80.00 | 81.78 | 82.22 | 82.78 |
AUC | 80.87 | 81.95 | 82.34 | 83.87 | 83.25 | 89.63 | |||
0.01 | 64 | ACC | 74.11 | 74.56 | 76.45 | 77.56 | 78.22 | 80.56 | |
AUC | 78.67 | 80.16 | 81.86 | 84.37 | 84.80 | 86.03 | |||
0.005 | 28 | ACC | 68.78 | 69.95 | 70.50 | 75.17 | 76.72 | 77.11 | |
AUC | 76.88 | 77.37 | 82.31 | 80.32 | 83.22 | 84.57 |
FST | Feature Selection Techniques |
USA | United State of America |
WCSRS | Wilcoxon Signed Rank Sum |
NB | Naïve Bayes |
AB | Adaboost |
LDA | Linear Discriminant Analysis |
ANN | Artificial Neural Network |
KNN | K-nearest Neighbor |
RF | Random Forest |
ACC | Accuracy |
AUC | Area Under Curve |
LASSO | Least Absolute Shrinkage and Selection Operator |
GSOA | Gravitational Search Optimization Algorithm |
EPO | Emperor Penguin Optimization |
hGSEPO | Hybrid Gravitational Search and Emperor Penguin Optimization |
ML | Machine Learning |
SVM | Support Vector Machine |
CART | Classification and Regression Tree |
| [1] |
Jones PA, Baylin SB. The Epigenomics of Cancer. Cell [Internet]. 2007 Feb 23 [cited 2025 Apr 13]; 128(4): 683-92. Available from:
https://www.cell.com/action/showFullText?pii=S0092867407001274 |
| [2] | Dasari S, Wudayagiri R, Valluru L. Cervical cancer: Biomarkers for diagnosis and treatment. Clin Chim Acta. 2015 May 20; 445: 7-11. |
| [3] |
Sung H, Ferlay J, … RSC a cancer journal, 2021 undefined. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. Wiley Online Libr Sung, J Ferlay, RL Siegel, M Laversanne, I Soerjomataram, A Jemal, F BrayCA a cancer J Clin 2021•Wiley Online Libr [Internet]. 2021 May [cited 2024 Sep 8]; 71(3): 209-49. Available from:
https://acsjournals.onlinelibrary.wiley.com/doi/abs/10.3322/caac.21660 |
| [4] | Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2022. CA Cancer J Clin [Internet]. 2022 Jan 1 [cited 2025 Apr 13]; 72(1): 7-33. Available from: |
| [5] | Sun YS, Zhao Z, Yang ZN, Xu F, Lu HJ, Zhu ZY, et al. Risk Factors and Preventions of Breast Cancer. Int J Biol Sci [Internet]. 2017 [cited 2025 Apr 13]; 13(11): 1387-97. Available from: |
| [6] | Altaf MM. A hybrid deep learning model for breast cancer diagnosis based on transfer learning and pulse-coupled neural networks. Math Biosci Eng 2021 55029 [Internet]. 2021 [cited 2025 Apr 13]; 18(5): 5029-46. Available from: |
| [7] | WHO. WHO EMRO | Breast Cancer Awareness Month 2022 | Campaigns | NCDs [Internet]. 2022 [cited 2025 Apr 13]. Available from: |
| [8] | Díaz-Uriarte R, bioinformatics SA de AB, 2006 undefined. Gene selection and classification of microarray data using random forest. SpringerR Díaz-Uriarte, S Alvarez AndrésBMC bioinformatics, 2006•Springer [Internet]. 2006 Jan 6 [cited 2024 Sep 8]; 7. Available from: |
| [9] |
Ruiz R, Riquelme J, Recognition JARP, 2006 U. Incremental wrapper-based gene selection from microarray data for cancer classification. ElsevierR Ruiz, JC Riquelme, JS Aguilar-RuizPattern Recognition, 2006•Elsevier [Internet]. 2006 [cited 2024 Sep 8]; Available from:
https://www.sciencedirect.com/science/article/pii/S0031320305004140 |
| [10] | Chen JJ, Chen CH. Microarray Gene Expression. 2003. |
| [11] |
González Calabozo JM, Peláez-Moreno C, Valverde-Albacete FJ. Gene Expression Array Exploration Using $\mathcal{K}$ -Formal Concept Analysis. Lect Notes Comput Sci (including Subser Lect Notes Artif Intell Lect Notes Bioinformatics) [Internet]. 2011 [cited 2024 Sep 10]; 6628 LNAI: 119-34. Available from:
https://www.infona.pl//resource/bwmeta1.element.springer-e61fdfa4-8690-3607-ba62-9b62807c030f |
| [12] |
Zhu Z, Ong Y, Recognition MDP, 2007 undefined. Markov blanket-embedded genetic algorithm for gene selection. ElsevierZ Zhu, YS Ong, M DashPattern Recognition, 2007 Elsevier [Internet]. 2007 [cited 2024 Sep 8]; Available from:
https://www.sciencedirect.com/science/article/pii/S0031320307000945 |
| [13] | Swaminathan M, Bhatti OW, Guo Y, Huang E, Akinwande O. Bayesian Learning for Uncertainty Quantification, Optimization, and Inverse Design. IEEE Trans Microw Theory Tech. 2022 Nov 1; 70(11): 4620-34. |
| [14] |
Delen D, Walker G, Kadam A. Predicting breast cancer survivability: a comparison of three data mining methods. Artif Intell Med [Internet]. 2005 Jun 1 [cited 2025 Jul 3]; 34(2): 113-27. Available from:
https://www.sciencedirect.com/science/article/abs/pii/S0933365704001010?via%3Dihub |
| [15] |
Freund Y, Schapire RE. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J Comput Syst Sci [Internet]. 1997 Aug 1 [cited 2025 Jul 3]; 55(1): 119-39. Available from:
https://www.sciencedirect.com/science/article/pii/S002200009791504X |
| [16] | McLachlan GJ. Discriminant Analysis and Statistical Pattern Recognition. 2004; 552. |
| [17] |
Kourou K, Exarchos TP, Exarchos KP, Karamouzis M V., Fotiadis DI. Machine learning applications in cancer prognosis and prediction. Comput Struct Biotechnol J [Internet]. 2015 Jan 1 [cited 2025 Jul 3]; 13: 8-17. Available from:
https://www.sciencedirect.com/science/article/pii/S2001037014000464 |
| [18] |
Lisboa PJ, Taktak AFG. The use of artificial neural networks in decision support in cancer: A systematic review. Neural Networks [Internet]. 2006 May 1 [cited 2025 Jul 3]; 19(4): 408-15. Available from:
https://www.sciencedirect.com/science/article/abs/pii/S0893608005002844 |
| [19] | Aha DW, Kibler D, Albert MK, Quinian JR. Instance-based learning algorithms. Mach Learn 1991 61 [Internet]. 1991 Jan [cited 2025 Jul 3]; 6(1): 37-66. Available from: |
| [20] | Chaurasia DV, Pal S. A Novel Approach for Breast Cancer Detection Using Data Mining Techniques. 2014 Jun 29 [cited 2025 Jul 3]; Available from: |
| [21] | Powers DMW, Ailab. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. 2020 Oct 11 [cited 2025 Jul 3]; Available from: |
| [22] |
Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett [Internet]. 2006 Jun 1 [cited 2025 Jul 3]; 27(8): 861-74. Available from:
https://www.sciencedirect.com/science/article/abs/pii/S016786550500303X |
| [23] | Akkur E, TURK F, Erogul O. Breast Cancer Diagnosis Using Feature Selection Approaches and Bayesian Optimization. Comput Syst Sci Eng [Internet]. 2022 Nov 3 [cited 2025 Jun 15]; 45(2): 1017-31. Available from: |
| [24] |
Naji MA, Filali S El, Aarika K, Benlahmar EH, Abdelouhahid RA, Debauche O. Machine Learning Algorithms For Breast Cancer Prediction And Diagnosis. Procedia Comput Sci [Internet]. 2021 Jan 1 [cited 2025 Jun 15]; 191: 487-92. Available from:
https://www.sciencedirect.com/science/article/pii/S1877050921014629 |
| [25] | López NC, García-Ordás MT, Vitelli-Storelli F, Fernández-Navarro P, Palazuelos C, Alaiz-Rodríguez R. Evaluation of Feature Selection Techniques for Breast Cancer Risk Prediction. Int J Environ Res Public Health [Internet]. 2021 Oct 1 [cited 2025 Jun 15]; 18(20): 10670. Available from: |
| [26] |
Singh LK, Khanna M, Singh R. Efficient feature selection for breast cancer classification using soft computing approach: A novel clinical decision support system. Multimed Tools Appl [Internet]. 2024 Apr 1 [cited 2025 Jun 15]; 83(14): 43223-76. Available from:
https://link.springer.com/article/10.1007/s11042-023-17044-8 |
| [27] |
Maniruzzaman M, Jahanur Rahman M, Ahammed B, Abedin MM, Suri HS, Biswas M, et al. Statistical characterization and classification of colon microarray gene expression data using multiple machine learning paradigms. Comput Methods Programs Biomed [Internet]. 2019 Jul 1 [cited 2025 Jun 15]; 176: 173-93. Available from:
https://www.sciencedirect.com/science/article/abs/pii/S0169260718317681 |
| [28] | Sharma A, Kulshrestha S, Daniel S. Machine learning approaches for breast cancer diagnosis and prognosis. 2017 Int Conf Soft Comput its Eng Appl Harnessing Soft Comput Tech Smart Better World, icSoftComp 2017. 2017 Jul 2; 2018-January: 1-5. |
| [29] | Islam T, Sheakh MA, Tahosin MS, Hena MH, Akash S, Bin Jardan YA, et al. Predictive modeling for breast cancer classification in the context of Bangladeshi patients by use of machine learning approach with explainable AI. Sci Rep [Internet]. 2024 Dec 1 [cited 2025 Jul 3]; 14(1): 1-17. Available from: |
| [30] | Ashika T, Grace GH. Enhancing Classification Performance through Rough Set Theory Feature Selection: A Comparative Study across Multiple Datasets. Eur J Pure Appl Math [Internet]. 2025 May 1 [cited 2025 Jul 3]; 18(2): 5934-5934. Available from: |
| [31] | Guyon I, Elisseeff A. An Introduction of Variable and Feature Selection. J Mach Learn Res. 2003; 1. |
| [32] | Saeys Y, Inza I, Larrañaga P. A review of feature selection techniques in bioinformatics. Bioinformatics [Internet]. 2007 Oct 1 [cited 2025 Jun 15]; 23(19): 2507-17. Available from: |
APA Style
Muna, M. R., Sarder, M. A. (2025). Statistical Test-Based Feature Selection and Classification Techniques for Breast Cancer Data. Machine Learning Research, 10(2), 124-130. https://doi.org/10.11648/j.mlr.20251002.13
ACS Style
Muna, M. R.; Sarder, M. A. Statistical Test-Based Feature Selection and Classification Techniques for Breast Cancer Data. Mach. Learn. Res. 2025, 10(2), 124-130. doi: 10.11648/j.mlr.20251002.13
@article{10.11648/j.mlr.20251002.13,
author = {Murfia Rahman Muna and Md. Alamgir Sarder},
title = {Statistical Test-Based Feature Selection and Classification Techniques for Breast Cancer Data
},
journal = {Machine Learning Research},
volume = {10},
number = {2},
pages = {124-130},
doi = {10.11648/j.mlr.20251002.13},
url = {https://doi.org/10.11648/j.mlr.20251002.13},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.mlr.20251002.13},
abstract = {Breast cancer is a disease that affects the majority of women and it is the second most common cause of death among women globally. Medical scientists have proven that there are a vast number of genes that are responsible for breast cancer. Among them, all genes are not equally responsible. Therefore, the most relevant and informative genes are needed to find out to control the disease. The objectives of our study are: (i) To find the most informative and significant genes using different statistical test-based feature selection techniques (FST) as well as find the best classifier and (ii) To validate our experimental results using a simulated dataset. The breast cancer dataset is a benchmark dataset provided by Kent Ridge Biomedical Data Repository, USA. In our study, we have used different statistical test-based feature selection techniques such as the t-test and Wilcoxon signed rank sum (WCSRS) test. Naïve Bayes (NB), Adaboost (AB), linear discriminant analysis (LDA), artificial neural network (ANN), k-nearest neighbor (KNN), and random forest (RF) are treated as classification techniques. Our analysis included 24,188 genes and 97 patients. Among them, 46 patients were with cancer and 51 were in control. We considered 70% of the dataset as a training set and the rest is a test set and repeated this procedure about 1000 times. Among all the combinations of FST and classification techniques t-test-based Naive Bayes classifier gives us the highest classification accuracy. The analysis of our study indicates that the integration of t-test-based FST and Naïve Bayes classifier produces the maximum classification accuracy.
},
year = {2025}
}
TY - JOUR T1 - Statistical Test-Based Feature Selection and Classification Techniques for Breast Cancer Data AU - Murfia Rahman Muna AU - Md. Alamgir Sarder Y1 - 2025/08/28 PY - 2025 N1 - https://doi.org/10.11648/j.mlr.20251002.13 DO - 10.11648/j.mlr.20251002.13 T2 - Machine Learning Research JF - Machine Learning Research JO - Machine Learning Research SP - 124 EP - 130 PB - Science Publishing Group SN - 2637-5680 UR - https://doi.org/10.11648/j.mlr.20251002.13 AB - Breast cancer is a disease that affects the majority of women and it is the second most common cause of death among women globally. Medical scientists have proven that there are a vast number of genes that are responsible for breast cancer. Among them, all genes are not equally responsible. Therefore, the most relevant and informative genes are needed to find out to control the disease. The objectives of our study are: (i) To find the most informative and significant genes using different statistical test-based feature selection techniques (FST) as well as find the best classifier and (ii) To validate our experimental results using a simulated dataset. The breast cancer dataset is a benchmark dataset provided by Kent Ridge Biomedical Data Repository, USA. In our study, we have used different statistical test-based feature selection techniques such as the t-test and Wilcoxon signed rank sum (WCSRS) test. Naïve Bayes (NB), Adaboost (AB), linear discriminant analysis (LDA), artificial neural network (ANN), k-nearest neighbor (KNN), and random forest (RF) are treated as classification techniques. Our analysis included 24,188 genes and 97 patients. Among them, 46 patients were with cancer and 51 were in control. We considered 70% of the dataset as a training set and the rest is a test set and repeated this procedure about 1000 times. Among all the combinations of FST and classification techniques t-test-based Naive Bayes classifier gives us the highest classification accuracy. The analysis of our study indicates that the integration of t-test-based FST and Naïve Bayes classifier produces the maximum classification accuracy. VL - 10 IS - 2 ER -
Statistics Discipline, Khulna University, Khulna, Bangladesh
Statistics Discipline, Khulna University, Khulna, Bangladesh
Information