Heart failure is a significant global health concern, contributing to high mortality rates and imposing substantial burdens on healthcare systems. Early prediction of mortality in heart failure patients can facilitate timely interventions, enhance patient management, and improve overall survival outcomes. This study applies machine learning techniques to predict death events among heart failure patients using clinical data. Five classification algorithms—Logistic Regression, Decision Tree, Random Forest, K-Nearest Neighbor (KNN), and Gaussian Naïve Bayes—are implemented on a dataset containing 5,000 patient records with 13 clinical attributes obtained from Kaggle. The research methodology includes extensive data preprocessing, such as missing value imputation using mean/mode strategies, standardization, feature selection via ANOVA P-value testing, and data balancing with the Synthetic Minority Over-sampling Technique (SMOTE). Model optimization was performed through hyperparameter tuning and cross-validation to enhance predictive accuracy. The results from two experimental settings—one without optimization and one with hyperparameter tuning, feature selection, and Principal Component Analysis (PCA)—show that K-Nearest Neighbor achieved the highest accuracy (98.5%) and precision (98.9%) after optimization. In contrast, Random Forest performed exceptionally well without tuning, achieving an accuracy of 99.2% and an F1-score of 98.7%. The findings demonstrate the effectiveness of machine learning in heart failure prognosis, providing valuable insights for clinical decision-making and personalized patient care.
| Published in | International Journal on Data Science and Technology (Volume 11, Issue 1) |
| DOI | 10.11648/j.ijdst.20251101.11 |
| Page(s) | 1-10 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Logistic Regression, Decision Tree, Random Forest, K-Nearest Neighbor, Gaussian Naïve Bayes, Heart Failure, Death Event
Experiment One | Experiment Two | |||||||
|---|---|---|---|---|---|---|---|---|
Accuracy (%) | F1-score (%) | Recall (%) | Precision (%) | Accuracy (%) | F1-score (%) | Recall (%) | Precision (%) | |
Logistic Regression | 81 | 72.2 | 79.2 | 66.3 | 82 | 81.6 | 81.2 | 82 |
Naïve Bayes | 84 | 73.5 | 68.4 | 79.6 | 83 | 82.2 | 79.7 | 84.8 |
Decision Tree | 98.7 | 97.9 | 98.4 | 97.5 | 97.5 | 97.4 | 96.6 | 98.3 |
Random Forest | 99.2 | 98.7 | 99 | 98.4 | 98.5 | 98.5 | 98.4 | 98.5 |
K-nearest Neighbor | 97.5 | 96 | 97.1 | 95 | 98.5 | 98.5 | 98 | 98.9 |
KNN | K-Nearest Neighbor |
PCA | Principal Component Analysis |
RFE | Recursive Feature Elimination |
ROC | Receiver Operating Characteristic |
| [1] | Bekhet, H. A. and Eletter, S. F. K. (2014) 'Credit risk assessment model for Jordanian commercial banks: Neural scoring approach', Review of Development Finance, 4(1), pp. 20-28. Available at: |
| [2] | Hosea, I. G. et al. (2023) 'A Machine Learning Approach to Fake News Detection Using Support Vector Machine (SVM) and Unsupervised Learning Model', Advances in Multidisciplinary and Scientific Research Journal Publication, 11(1), pp. 11. Available at: |
| [3] | J. Sepúlveda and S. A. Velastın (2015) 'F1 score assesment of gaussian mixture background subtraction algorithms using the MuHAVi dataset', 6th International Conference on Imaging for Crime Prevention and Detection (ICDP-15). Available at: |
| [4] | Joshi, G. (2022) 'Distributed Optimization in Machine Learning', in 'Distributed Optimization in Machine Learning', pp. 1-12. |
| [5] | K. Yadav and S. Singh (2023) 'Loan Status Prediction using SVM and Logistic Regression', 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT). Available at: |
| [6] | Li, J., Sun, Y., Ren, J., Wu, Y., & He, Z. (2024). "Machine Learning for In-hospital Mortality Prediction in Critically Ill Patients With Acute Heart Failure: A Retrospective Analysis Based on the MIMIC-IV Database." Journal of Cardiothoracic and Vascular Anesthesia. Available at: |
| [7] | Makam, P., & Janardhan, G. (2024). "Voice-Driven Mortality Prediction in Hospitalized Heart Failure Patients: A Machine Learning Approach Enhanced with Diagnostic Biomarkers." arXiv preprint arXiv: 2402. 13812. Available at: |
| [8] | P. Makam and G. Janardhan (2023) 'Survival Analysis of Heart Failure Patients Using Advanced Machine Learning Techniques', 2023 International Conference on Advanced & Global Engineering Challenges (AGEC). Available at: |
| [9] | Ravulapalli, L. T. et al. (2023) 'Evaluative Study of Machine Learning Classifiers in Predicting Heart Failure: A Focus on Imbalanced Datasets', Ingénierie Des Systèmes D'Information, 28(3), pp. 717-724. Available at: |
| [10] | S. Jamal, W. A. Elenin and L. Chen (2023) 'Developing and Evaluating Data-Driven Heart Disease Prediction Models by Ensemble Methods on Different Data Mining Tools', 2023 IEEE 14th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON). Available at: |
| [11] | Shi, Y., et al. (2023). "Enhancing Mortality Prediction in Heart Failure Patients: Exploring Preprocessing Methods for Imbalanced Clinical Datasets." arXiv preprint arXiv: 2310. 00457. Available at: |
| [12] | Y. Shi et al. (2021) 'Efficient Jamming Identification in Wireless Communication: Using Small Sample Data Driven Naive Bayes Classifier', IEEE Wireless Communications Letters, 10(7), pp. 1375-1379. Available at: |
| [13] | Z. Fan et al. (2024) 'Multiview Adaptive K-Nearest Neighbor Classification', IEEE Transactions on Artificial Intelligence, 5(3), pp. 1221-1234. Available at: |
| [14] | Zhang, T., et al. (2024). "Random Forest and Deep Learning Approaches for Mortality Risk Assessment in Heart Failure Patients." Computational and Mathematical Methods in Medicine, 2024, Article ID 1354827. Available at: |
APA Style
Gungbias, H. I., Kassem, M. H. (2025). Death Events from Heart Failure Prediction Using Machine Learning Approach. International Journal on Data Science and Technology, 11(1), 1-10. https://doi.org/10.11648/j.ijdst.20251101.11
ACS Style
Gungbias, H. I.; Kassem, M. H. Death Events from Heart Failure Prediction Using Machine Learning Approach. Int. J. Data Sci. Technol. 2025, 11(1), 1-10. doi: 10.11648/j.ijdst.20251101.11
@article{10.11648/j.ijdst.20251101.11,
author = {Hosea Isaac Gungbias and Mulapnen Haruna Kassem},
title = {Death Events from Heart Failure Prediction Using Machine Learning Approach
},
journal = {International Journal on Data Science and Technology},
volume = {11},
number = {1},
pages = {1-10},
doi = {10.11648/j.ijdst.20251101.11},
url = {https://doi.org/10.11648/j.ijdst.20251101.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijdst.20251101.11},
abstract = {Heart failure is a significant global health concern, contributing to high mortality rates and imposing substantial burdens on healthcare systems. Early prediction of mortality in heart failure patients can facilitate timely interventions, enhance patient management, and improve overall survival outcomes. This study applies machine learning techniques to predict death events among heart failure patients using clinical data. Five classification algorithms—Logistic Regression, Decision Tree, Random Forest, K-Nearest Neighbor (KNN), and Gaussian Naïve Bayes—are implemented on a dataset containing 5,000 patient records with 13 clinical attributes obtained from Kaggle. The research methodology includes extensive data preprocessing, such as missing value imputation using mean/mode strategies, standardization, feature selection via ANOVA P-value testing, and data balancing with the Synthetic Minority Over-sampling Technique (SMOTE). Model optimization was performed through hyperparameter tuning and cross-validation to enhance predictive accuracy. The results from two experimental settings—one without optimization and one with hyperparameter tuning, feature selection, and Principal Component Analysis (PCA)—show that K-Nearest Neighbor achieved the highest accuracy (98.5%) and precision (98.9%) after optimization. In contrast, Random Forest performed exceptionally well without tuning, achieving an accuracy of 99.2% and an F1-score of 98.7%. The findings demonstrate the effectiveness of machine learning in heart failure prognosis, providing valuable insights for clinical decision-making and personalized patient care.
},
year = {2025}
}
TY - JOUR T1 - Death Events from Heart Failure Prediction Using Machine Learning Approach AU - Hosea Isaac Gungbias AU - Mulapnen Haruna Kassem Y1 - 2025/03/11 PY - 2025 N1 - https://doi.org/10.11648/j.ijdst.20251101.11 DO - 10.11648/j.ijdst.20251101.11 T2 - International Journal on Data Science and Technology JF - International Journal on Data Science and Technology JO - International Journal on Data Science and Technology SP - 1 EP - 10 PB - Science Publishing Group SN - 2472-2235 UR - https://doi.org/10.11648/j.ijdst.20251101.11 AB - Heart failure is a significant global health concern, contributing to high mortality rates and imposing substantial burdens on healthcare systems. Early prediction of mortality in heart failure patients can facilitate timely interventions, enhance patient management, and improve overall survival outcomes. This study applies machine learning techniques to predict death events among heart failure patients using clinical data. Five classification algorithms—Logistic Regression, Decision Tree, Random Forest, K-Nearest Neighbor (KNN), and Gaussian Naïve Bayes—are implemented on a dataset containing 5,000 patient records with 13 clinical attributes obtained from Kaggle. The research methodology includes extensive data preprocessing, such as missing value imputation using mean/mode strategies, standardization, feature selection via ANOVA P-value testing, and data balancing with the Synthetic Minority Over-sampling Technique (SMOTE). Model optimization was performed through hyperparameter tuning and cross-validation to enhance predictive accuracy. The results from two experimental settings—one without optimization and one with hyperparameter tuning, feature selection, and Principal Component Analysis (PCA)—show that K-Nearest Neighbor achieved the highest accuracy (98.5%) and precision (98.9%) after optimization. In contrast, Random Forest performed exceptionally well without tuning, achieving an accuracy of 99.2% and an F1-score of 98.7%. The findings demonstrate the effectiveness of machine learning in heart failure prognosis, providing valuable insights for clinical decision-making and personalized patient care. VL - 11 IS - 1 ER -
Computer Science Department, Plateau State University, Bokkos, Nigeria
Computer Science Department, Plateau State University, Bokkos, Nigeria

Figure 1. Research Framework.
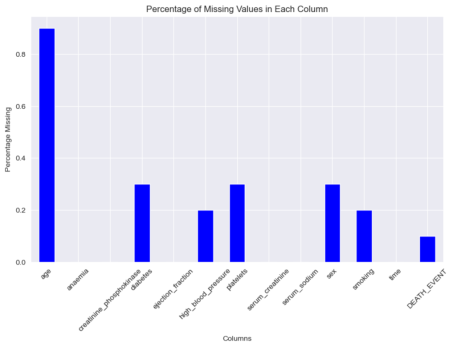
Figure 2. Percentage of missing values.
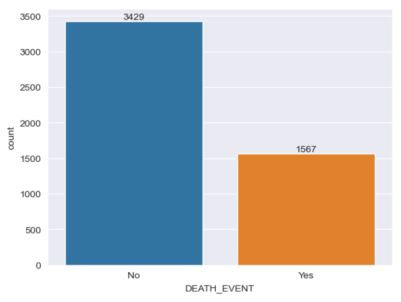
Figure 3. Target variable showing imbalanced data.
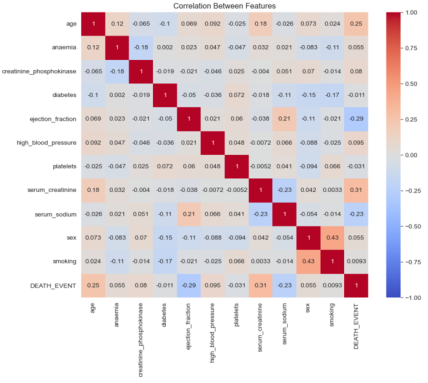
Figure 4. Correlation matrix between features.
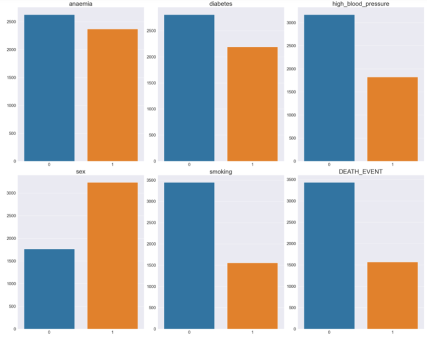
Figure 5. Distribution of Categorical data.
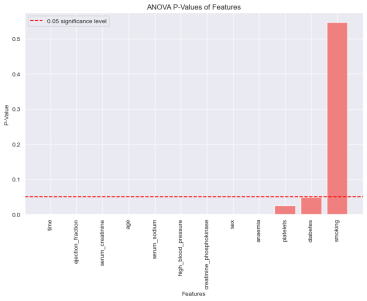
Figure 6. Significant Features.
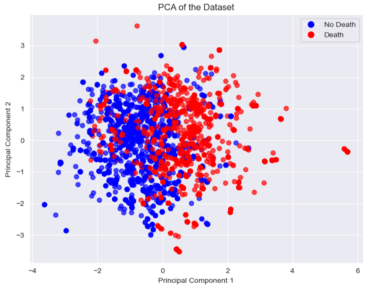
Figure 7. PCA of the data.

Figure 8. Data balancing.
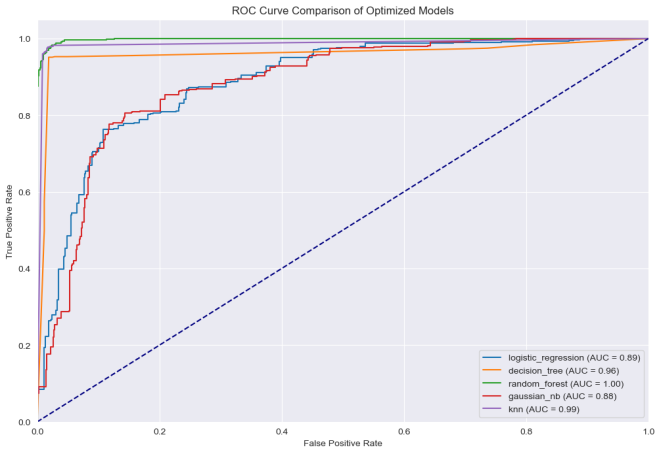
Figure 9. Experiment One ROC-Curve.
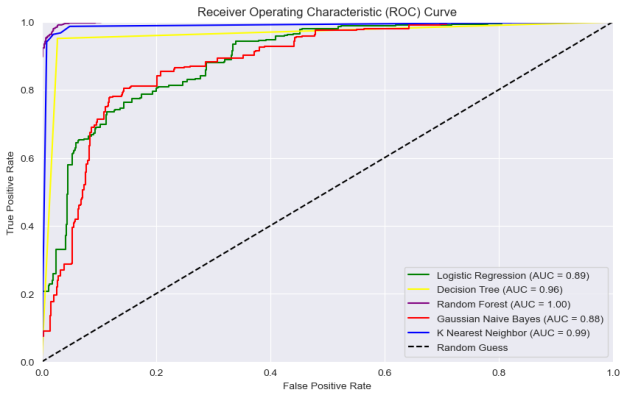
Figure 10. Experiment Two ROC-Curve.
Information

