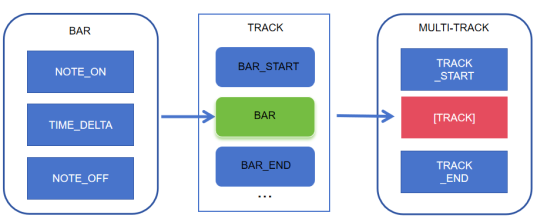
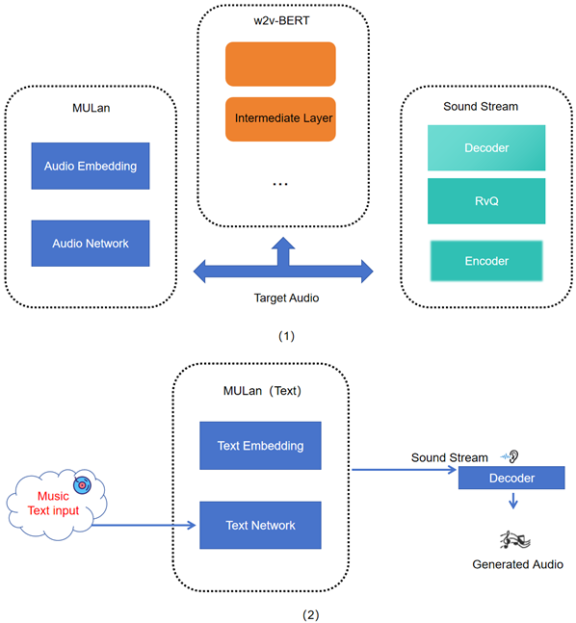
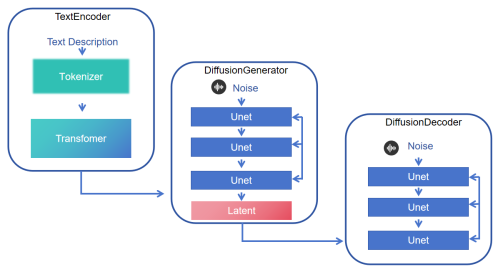
Due to the swift advancement of artificial intelligence and deep learning technologies, computers are assuming an increasingly prominent role in the realm of music composition, thereby fueling innovations in techniques for music generation. Deep learning models such as RNNs, LSTMs, Transformers, and diffusion models have demonstrated outstanding performance in the music generation process, effectively handling temporal relationships, long-term dependencies, and complex structural issues in music. Transformers, with their self-attention mechanism, excel at capturing long-term dependencies and generating intricate melodies, while diffusion models exhibit significant advantages in audio quality, producing higher-fidelity and more natural audio. Despite these breakthroughs in generation quality and performance, challenges remain in areas such as efficiency, originality, and structural coherence. This research undertakes a comprehensive examination of the utilization of diverse and prevalent deep learning frameworks in music generation, emphasizing their respective advantages and constraints in managing temporal correlations, prolonged dependencies, and intricate structures. It aims to provide insights to address current challenges in efficiency and control capabilities. Additionally, the research explores the potential applications of these technologies in fields such as music education, therapy, and entertainment, offering theoretical and practical guidance for future music creation and applications. Furthermore, this study highlights the importance of addressing the limitations of current models, such as the computational intensity of Transformers and the slow generation speed of diffusion models, to pave the way for more efficient and creative music generation systems. Future work may focus on combining the strengths of different models to overcome these challenges and to foster greater originality and diversity in AI-generated music. By doing so, we aim to push the boundaries of what is possible in music creation, leveraging the power of AI to inspire new forms of artistic expression and enhance the creative process for musicians and composers alike.
| Published in | American Journal of Information Science and Technology (Volume 9, Issue 3) |
| DOI | 10.11648/j.ajist.20250903.11 |
| Page(s) | 155-162 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Artificial Intelligence, Deep Learning, Music Generation, Transformers
Base Model | Advantages | Limitations | Typical Application Examples |
|---|---|---|---|
CNN [13] | Efficient at capturing local features, suitable for audio waveform generation | Struggles with long-range dependencies | High-fidelity audio waveform generation |
RNN | Good at handling time series data, suitable for generating coherent music sequences | Vanishing/exploding gradients, long-term de-pendency issues | Coherent music sequence generation |
LSTM | Effectively captures long-term dependencies, suitable for generating complex music structures | High computational complexity, but more stable than RNN | Bach Bot generating Bach-style music [14] |
GAN | Generates high-quality, realistic audio content | Unstable training, may lack coherence | DCGAN [15] and Wave-GAN [16] generating high-quality audio waveforms |
Transformer | Excels at capturing long-range dependencies and complex structures, can generate music based on text | Complex training process, high computational cost | MusicLM [18] generating music consistent with text descriptions |
Diffusion Model | Generates high-quality audio, suitable for high-fidelity music generation | High computational cost, slower generation speed | Moûsai [22] generating music based on text descriptions |
AI | Artificial Intelligence |
DL | Deep Learning |
RNN | Recurrent Neural Network |
LSTM | Long Short-Term Memory |
CNN | Convolutional Neural Network |
VAE | Variational Autoencoder |
| [1] | Zhu, Y., Baca, J., Rekabdar, B., & Rawassizadeh, R. (2023). A Survey of AI Music Generation Tools and Models. arXiv preprint |
| [2] | Zhao, J., Huang, F., Lv, J., Duan, Y., Qin, Z., Li, G., & Tian, G. (2020, November). Do RNN and LSTM have long memory. In International Conference on Machine Learning (pp. 11365-11375). PMLR. Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems. |
| [3] | Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems. |
| [4] | Hsiao W Y, Liu J Y, Yeh Y C, et al. Compound word transformer: Learning to compose full-song music over dynamic directed hypergraphs[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(1): 178-186. |
| [5] | Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851. |
| [6] | Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv preprint |
| [7] | Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780. |
| [8] | Kong, Q., Li, B., Chen, J., & Wang, Y. (2020). Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv: 2009.09761. |
| [9] | Yang, L. (2024). The Importance of Dual Piano Performance Forms in Piano Performance in the Context of Deep Learning. Applied Mathematics and Nonlinear Sciences, 9(1). |
| [10] | Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors, 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. |
| [11] | Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Curtis Hawthorne, Andrew M Dai, Matthew D Hoffman, and Douglas Eck. Music transformer: Generating music with long-term structure. |
| [12] | Jeff Ens and Philippe Pasquier. Mmm: Exploring conditional multi-track music generation with the transformer. arXiv preprint |
| [13] | Oord A. WaveNet: A Generative Model for Raw Audio [J]. arXiv preprint |
| [14] | Liang, F. (2016). Bachbot: Automatic composition in the style of bach chorales. University of Cambridge, 8(19-48), 3-1. |
| [15] | Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training gans. Advances in neural information processing systems, 29. |
| [16] | Donahue, C., McAuley, J., & Puckette, M. (2018). Adversarial audio synthesis. arXiv preprint |
| [17] | Chen, Y., Huang, L., & Gou, T. (2024). Applications and Advances of Artificial Intelligence in Music Generation: A Review.. |
| [18] | Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A.,... & Frank, C. (2023). Musiclm: Generating music from text. |
| [19] | Huang, Q., Jansen, A., Lee, J., Ganti, R., Li, J. Y., & Ellis, D. P. (2022). Mulan: A joint embedding of music audio and natural language. |
| [20] | Chung, Y. A., Zhang, Y., Han, W., Chiu, C. C., Qin, J., Pang, R., & Wu, Y. (2021, December). W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 244-250). IEEE. |
| [21] | Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., & Tagliasacchi, M. (2021). Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 495-507. |
| [22] | Schneider, F., Kamal, O., Jin, Z., & Schölkopf, B. (2024, August). Moûsai: Efficient text-to-music diffusion models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 8050-8068). |
| [23] | Pachet, F. (2003). The continuator: Musical interaction with style. Journal of New Music Research, 32(3), 333-341. |
| [24] | Briot, J. P., Hadjeres, G., & Pachet, F. D. (2020). Deep learning techniques for music generation (Vol. 1). Heidelberg: Springer. |
| [25] | Aalbers, S., Fusar-Poli, L., Freeman, R. E., Spreen, M., Ket, J. C., Vink, A. C.,... & Gold, C. (2017). Music therapy for depression. Cochrane database of systematic reviews, (11). |
| [26] | Sacks, O. (2008). Musicophilia. Tales of Music and the Brain. London (Picador) 2008. |
| [27] | Singh, P. Media 2.0: A Journey through AI-Enhanced Communication and Content. Media and Al: Navigating, 127. |
| [28] | Gan, C., Huang, D., Chen, P., Tenenbaum, J. B., & Torralba, A. (2020). Foley music: Learning to generate music from videos. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16 (pp. 758-775). Springer International Publishing. |
| [29] | Björk, S., & Holopainen, J. (2005). Games and design patterns. The game design reader: A rules of play anthology, 410-437. |
| [30] | Briot, J. P., & Pachet, F. (2020). Deep learning for music generation: challenges and directions. Neural Computing and Applications, 32(4), 981-993. |
APA Style
Yanjun, C. (2025). Features, Models, and Applications of Deep Learning in Music Composition. American Journal of Information Science and Technology, 9(3), 155-162. https://doi.org/10.11648/j.ajist.20250903.11
ACS Style
Yanjun, C. Features, Models, and Applications of Deep Learning in Music Composition. Am. J. Inf. Sci. Technol. 2025, 9(3), 155-162. doi: 10.11648/j.ajist.20250903.11
@article{10.11648/j.ajist.20250903.11,
author = {Chen Yanjun},
title = {Features, Models, and Applications of Deep Learning in Music Composition
},
journal = {American Journal of Information Science and Technology},
volume = {9},
number = {3},
pages = {155-162},
doi = {10.11648/j.ajist.20250903.11},
url = {https://doi.org/10.11648/j.ajist.20250903.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajist.20250903.11},
abstract = {Due to the swift advancement of artificial intelligence and deep learning technologies, computers are assuming an increasingly prominent role in the realm of music composition, thereby fueling innovations in techniques for music generation. Deep learning models such as RNNs, LSTMs, Transformers, and diffusion models have demonstrated outstanding performance in the music generation process, effectively handling temporal relationships, long-term dependencies, and complex structural issues in music. Transformers, with their self-attention mechanism, excel at capturing long-term dependencies and generating intricate melodies, while diffusion models exhibit significant advantages in audio quality, producing higher-fidelity and more natural audio. Despite these breakthroughs in generation quality and performance, challenges remain in areas such as efficiency, originality, and structural coherence. This research undertakes a comprehensive examination of the utilization of diverse and prevalent deep learning frameworks in music generation, emphasizing their respective advantages and constraints in managing temporal correlations, prolonged dependencies, and intricate structures. It aims to provide insights to address current challenges in efficiency and control capabilities. Additionally, the research explores the potential applications of these technologies in fields such as music education, therapy, and entertainment, offering theoretical and practical guidance for future music creation and applications. Furthermore, this study highlights the importance of addressing the limitations of current models, such as the computational intensity of Transformers and the slow generation speed of diffusion models, to pave the way for more efficient and creative music generation systems. Future work may focus on combining the strengths of different models to overcome these challenges and to foster greater originality and diversity in AI-generated music. By doing so, we aim to push the boundaries of what is possible in music creation, leveraging the power of AI to inspire new forms of artistic expression and enhance the creative process for musicians and composers alike.},
year = {2025}
}
TY - JOUR T1 - Features, Models, and Applications of Deep Learning in Music Composition AU - Chen Yanjun Y1 - 2025/07/15 PY - 2025 N1 - https://doi.org/10.11648/j.ajist.20250903.11 DO - 10.11648/j.ajist.20250903.11 T2 - American Journal of Information Science and Technology JF - American Journal of Information Science and Technology JO - American Journal of Information Science and Technology SP - 155 EP - 162 PB - Science Publishing Group SN - 2640-0588 UR - https://doi.org/10.11648/j.ajist.20250903.11 AB - Due to the swift advancement of artificial intelligence and deep learning technologies, computers are assuming an increasingly prominent role in the realm of music composition, thereby fueling innovations in techniques for music generation. Deep learning models such as RNNs, LSTMs, Transformers, and diffusion models have demonstrated outstanding performance in the music generation process, effectively handling temporal relationships, long-term dependencies, and complex structural issues in music. Transformers, with their self-attention mechanism, excel at capturing long-term dependencies and generating intricate melodies, while diffusion models exhibit significant advantages in audio quality, producing higher-fidelity and more natural audio. Despite these breakthroughs in generation quality and performance, challenges remain in areas such as efficiency, originality, and structural coherence. This research undertakes a comprehensive examination of the utilization of diverse and prevalent deep learning frameworks in music generation, emphasizing their respective advantages and constraints in managing temporal correlations, prolonged dependencies, and intricate structures. It aims to provide insights to address current challenges in efficiency and control capabilities. Additionally, the research explores the potential applications of these technologies in fields such as music education, therapy, and entertainment, offering theoretical and practical guidance for future music creation and applications. Furthermore, this study highlights the importance of addressing the limitations of current models, such as the computational intensity of Transformers and the slow generation speed of diffusion models, to pave the way for more efficient and creative music generation systems. Future work may focus on combining the strengths of different models to overcome these challenges and to foster greater originality and diversity in AI-generated music. By doing so, we aim to push the boundaries of what is possible in music creation, leveraging the power of AI to inspire new forms of artistic expression and enhance the creative process for musicians and composers alike. VL - 9 IS - 3 ER -
College of Music and Dance, Divion of Arts, Shenzhen University, Shenzhen, China
Information