Supervised learning is mainly used to optimize Adaptive Neural Fuzzy Inference System (ANFIS) controllers. In order to generate data for supervised learning, a controller is designed and optimized using Particle Swarm Optimization (PSO) or any other algorithms. This paper proposes and compares reinforcement learning based ANFIS and Approximate Reasoning Intelligent controller (ARIC) controllers. Reinforcement learning based ANFIS reduces the work flow required to train it by directly optimizing the membership functions using Proximal Policy Optimization (PPO) algorithm. ANFIS and ARIC neuro fuzzy controllers are designed for nonlinear dynamics of coffee roasting process using Schwartzberg’s model. A custom layer is designed for every membership function and fuzzy inference operations using MATLAB’s Deep Learning Toolbox. This neural connectionist model of ANFIS and ARIC is used as actor. The critic which evaluates the goodness of action taken is a two-layer neural network with sigmoidal activation function. Simulink environment is also created to represent the dynamics of coffee roasting process. The agent is trained to track roast profile for 50 episodes. The training converged at 50th iteration. After training, the Root Mean Square Error (RMSE) for ARIC architecture reduced from 0.5134 to 0.08122. Similarly, the RMSE of ANFIS improved from 0.2026 to 0.0624.
| Published in | Automation, Control and Intelligent Systems (Volume 13, Issue 2) |
| DOI | 10.11648/j.acis.20251302.12 |
| Page(s) | 31-48 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Reinforcement Learning, ANFIS, ARIC, PPO, Schwartzberg Model, Spouted Bed Roasting
e | ||||
|---|---|---|---|---|
de | NbE | NsE | PsE | PbE |
NdE | LV | LV | MLV | HV |
ZdE | LV | MLV | MHV | HV |
PdE | LV | MHV | HV | HV |
Membership Function | Before Optimization | Learnable Parameters |
|---|---|---|
Negative big error | [-20 -20 -2 -1] | [-20 -20 c d] |
Negative small error | [-2 -1 0.1] | [a b 0.1] |
Positive small Error | [-0.1 1 2] | [-0.1 b c] |
Positive big Error | [1 2 300 300] | [a b 300 300] |
Negative error derivative | [-0.01 -0.01 -0.002 0] | None |
Zero error derivative | [-0.002 0 0.002] | None |
Positive error derivative | [0 0.02 0.01 0.01] | None |
Low Voltage | [-20 -20 125] | [b b c] |
Medium Low Voltage | [100 150 200] | [a 150 b] |
Medium High Voltage | [160 200 240] | [a 200 b] |
High Voltage | [200 240 240] | [a b b] |
Membership Function | Before Optimization | Learnable Parameters |
|---|---|---|
Negative big error | [-20 -20 -2 -1] | [-20 -20 c d] |
Negative small error | [-2 -1 0.1] | [a b 0.1] |
Positive small Error | [-0.1 1 2] | [-0.1 b c] |
Positive big Error | [1 2 300 300] | [a b 300 300] |
Negative error derivative | [-0.01 -0.01 -0.002 0] | None |
Zero error derivative | [-0.002 0 0.002] | None |
Positive error derivative | [0 0.02 0.01 0.01] | None |
Low Voltage | [1 1 22.75] | [a b c] |
Medium Low Voltage | [1 1 150] | [a b c] |
Medium High Voltage | [1 1 200] | [a b c] |
High Voltage | [1 1 227.5] | [a b c] |
Membership Function | Before Optimization | Learnable Parameters |
|---|---|---|
Negative big error | [-20 -20 -2 -1] | [-20 -20 -0.029004676 -6.4834234e-07] |
Negative small error | [-2 -1 0.1] | [-0.029004676 -6.4834234e-07 0.1] |
Positive small Error | [-0.1 1 2] | [-0.1 6.4834234e-07 0.029004676] |
Positive big Error | [1 2 300 300] | [6.4834234e-07 0.029004676 300 300] |
Negative error derivative | [-0.01 -0.01 -0.002 0] | None |
Zero error derivative | [-0.002 0 0.002] | None |
Positive error derivative | [0 0.02 0.01 0.01] | None |
Low Voltage | [1 1 22.75] | [6.4834234e-07 6.4834234e-07 23.780174] |
Medium Low Voltage | [1 1 150] | [6.4834234e-07 6.4834234e-07 146.25401] |
Medium High Voltage | [1 1 200] | [6.4834234e-07 6.4834234e-07 196.25311] |
High Voltage | [1 1 227.5] | [6.4834234e-07 6.4834234e-07 223.75261] |
AEN | Action Evaluation Network |
ANFIS | Adaptive Neural Fuzzy Inference System |
ARIC | Approximate Reasoning Intelligent Controller |
ASN | Action Selection Network |
FIS | Fuzzy Inference System |
GARIC | Generalized Approximate Reasoning Intelligent Controller |
MOA | Mayfly Optimization Algorithm |
MPO | Maximum Aposteriori Policy Optimization |
MPPT | Maximum Power Point Tracking |
MSM | Magnetic Shape Memory |
PID | Proportional Integral Derivative |
PPO | Proximal Policy Optimization |
PSO | Particle Swarm Optimization |
RGA | Relative Gain Array |
SAM | Stochastic Action Modifier |
| [1] | A. Abraham, “BEYOND INTEGRATED NEURO-FUZZY SYSTEMS: REVIEWS, PROSPECTS, PERSPECTIVES AND DIRECTIONS.” [Online]. Available: |
| [2] | Petrovic, K. Macek, and N. Peru, “A KNOWLEDGE-BASE GENERATING FUZZY-NEURAL CONTROLLER,” 2000. |
| [3] | M. Zhou, B. Hu, W. Gao, and J. Wang, “Reinforcement Learning Fuzzy Neural Network Control for Magnetic Shape Memory Alloy Actuator,” International Journal of Control and Automation, vol. 7, no. 6, pp. 109-122, Jun. 2014, |
| [4] | S. Rößler et al., “Two types of magnetic shape-memory effects from twinned microstructure and magneto-structural coupling in Fe1+yTe,” Proc Natl Acad Sci U S A, vol. 116, no. 34, pp. 16697-16702, Aug. 2019, |
| [5] | M. H. F. Zarandi, J. Jouzdani, and I. B. Turksen, “Generalized reinforcement learning fuzzy control with vague states,” Advances in Soft Computing, vol. 41, pp. 811-820, 2007, |
| [6] | N. T. T. Vu, H. D. Nguyen, and A. T. Nguyen, “Reinforcement Learning-Based Adaptive Optimal Fuzzy MPPT Control for Variable Speed Wind Turbine,” IEEE Access, vol. 10, pp. 95771-95780, 2022, |
| [7] | M. Ali, T. Fahmi, H. Nurohmah, H. Suyono, and M. A. Muslim, “Optimization on PID and ANFIS Controller on Dual Axis Tracking for Photovoltaic Based on Firefly Algorithm.” |
| [8] | H. Vinh Nguyen, H. Chi Minh City, H. Nguyen, M. Tien Cao, and K. Hung Le, “Performance Comparison between PSO and GA in Improving Dynamic Voltage Stability in ANFIS Controllers for STATCOM,” 2019. [Online]. Available: |
| [9] | N. Hamouda, B. Babes, S. Kahla, A. Boutaghane, A. Beddar, and O. Aissa, “ANFIS Controller Design Using PSO Algorithm for MPPT of Solar PV System Powered Brushless DC Motor Based Wire Feeder Unit,” in 2020 International Conference on Electrical Engineering, ICEE 2020, Sep. 2020. |
| [10] | B. Selma, S. Chouraqui, and U. Artois, “Hybrid ANFIS-ant colony based optimisation for quadrotor trajectory tracking control Hassane Abouaïssa,” 2020. |
| [11] | M. Chen, H. K. Lam, Q. Shi, and B. Xiao, “Reinforcement Learning-Based Control of Nonlinear Systems Using Lyapunov Stability Concept and Fuzzy Reward Scheme,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 67, no. 10, pp. 2059-2063, Oct. 2020, |
| [12] | W. He, H. Gao, C. Zhou, C. Yang, and Z. Li, “Reinforcement Learning Control of a Flexible Two-Link Manipulator: An Experimental Investigation,” IEEE Trans Syst Man Cybern Syst, vol. 51, no. 12, pp. 7326-7336, Dec. 2021, |
| [13] | J. Degrave et al., “Magnetic control of tokamak plasmas through deep reinforcement learning,” Nature, vol. 602, no. 7897, pp. 414-419, Feb. 2022, |
| [14] | A. Allen, L. Allen, D. Geier, B. Miller, F. Advisor, and R. Diersing, “Fluid-Bed Coffee Roaster.” [Online]. Available: |
| [15] | C. T. (Ching T. Lin and C. S. G. (C. S. G. Lee, Neural fuzzy systems: a neuro-fuzzy synergism to intelligent systems. Prentice Hall PTR, 1996. |
| [16] | H. R. Berenji, “A Reinforcement Learning-Based Architecture for Fuzzy Logic Control,” 1992. |
| [17] | Hung T. Nguyen and Michio Sugeno, Fuzzy Systems. Springer US, 1998. |
| [18] | Nikam S R, N. P. J. And, and Kulkarni S P, “FUZZY LOGIC AND NEURO-FUZZY MODELING Journal of Artificial Intelligence,” vol. 3, no. 2, 2012, [Online]. Available: |
| [19] | H. R. Berenji and P. Khedkar, “Learning and Tuning Fuzzy Logic Controllers Through Reinforcements,” 1992. |
APA Style
Amare, A., Seid, S. (2025). Reinforcement Learning Based Neuro-fuzzy Controller for Coffee Roasting Process. Automation, Control and Intelligent Systems, 13(2), 31-48. https://doi.org/10.11648/j.acis.20251302.12
ACS Style
Amare, A.; Seid, S. Reinforcement Learning Based Neuro-fuzzy Controller for Coffee Roasting Process. Autom. Control Intell. Syst. 2025, 13(2), 31-48. doi: 10.11648/j.acis.20251302.12
@article{10.11648/j.acis.20251302.12,
author = {Abiy Amare and Solomon Seid},
title = {Reinforcement Learning Based Neuro-fuzzy Controller for Coffee Roasting Process
},
journal = {Automation, Control and Intelligent Systems},
volume = {13},
number = {2},
pages = {31-48},
doi = {10.11648/j.acis.20251302.12},
url = {https://doi.org/10.11648/j.acis.20251302.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.acis.20251302.12},
abstract = {Supervised learning is mainly used to optimize Adaptive Neural Fuzzy Inference System (ANFIS) controllers. In order to generate data for supervised learning, a controller is designed and optimized using Particle Swarm Optimization (PSO) or any other algorithms. This paper proposes and compares reinforcement learning based ANFIS and Approximate Reasoning Intelligent controller (ARIC) controllers. Reinforcement learning based ANFIS reduces the work flow required to train it by directly optimizing the membership functions using Proximal Policy Optimization (PPO) algorithm. ANFIS and ARIC neuro fuzzy controllers are designed for nonlinear dynamics of coffee roasting process using Schwartzberg’s model. A custom layer is designed for every membership function and fuzzy inference operations using MATLAB’s Deep Learning Toolbox. This neural connectionist model of ANFIS and ARIC is used as actor. The critic which evaluates the goodness of action taken is a two-layer neural network with sigmoidal activation function. Simulink environment is also created to represent the dynamics of coffee roasting process. The agent is trained to track roast profile for 50 episodes. The training converged at 50th iteration. After training, the Root Mean Square Error (RMSE) for ARIC architecture reduced from 0.5134 to 0.08122. Similarly, the RMSE of ANFIS improved from 0.2026 to 0.0624.},
year = {2025}
}
TY - JOUR T1 - Reinforcement Learning Based Neuro-fuzzy Controller for Coffee Roasting Process AU - Abiy Amare AU - Solomon Seid Y1 - 2025/08/26 PY - 2025 N1 - https://doi.org/10.11648/j.acis.20251302.12 DO - 10.11648/j.acis.20251302.12 T2 - Automation, Control and Intelligent Systems JF - Automation, Control and Intelligent Systems JO - Automation, Control and Intelligent Systems SP - 31 EP - 48 PB - Science Publishing Group SN - 2328-5591 UR - https://doi.org/10.11648/j.acis.20251302.12 AB - Supervised learning is mainly used to optimize Adaptive Neural Fuzzy Inference System (ANFIS) controllers. In order to generate data for supervised learning, a controller is designed and optimized using Particle Swarm Optimization (PSO) or any other algorithms. This paper proposes and compares reinforcement learning based ANFIS and Approximate Reasoning Intelligent controller (ARIC) controllers. Reinforcement learning based ANFIS reduces the work flow required to train it by directly optimizing the membership functions using Proximal Policy Optimization (PPO) algorithm. ANFIS and ARIC neuro fuzzy controllers are designed for nonlinear dynamics of coffee roasting process using Schwartzberg’s model. A custom layer is designed for every membership function and fuzzy inference operations using MATLAB’s Deep Learning Toolbox. This neural connectionist model of ANFIS and ARIC is used as actor. The critic which evaluates the goodness of action taken is a two-layer neural network with sigmoidal activation function. Simulink environment is also created to represent the dynamics of coffee roasting process. The agent is trained to track roast profile for 50 episodes. The training converged at 50th iteration. After training, the Root Mean Square Error (RMSE) for ARIC architecture reduced from 0.5134 to 0.08122. Similarly, the RMSE of ANFIS improved from 0.2026 to 0.0624. VL - 13 IS - 2 ER -
Electromechanical Engineering Department, Addis Ababa Science and Technology University, Addis Ababa, Ethiopia
Reverse Engineering, Bio and Emerging Technology Institute, Addis Ababa, Ethiopia
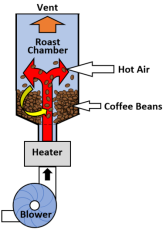
Figure 1. Spouted bed coffee roaster [14].
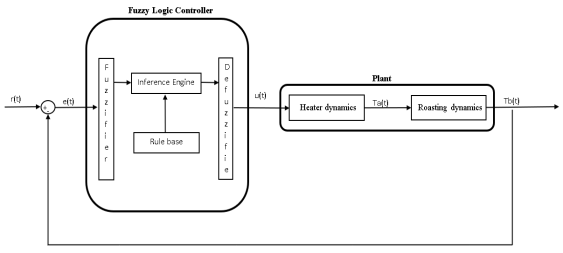
Figure 2. Fuzzy controller structure.
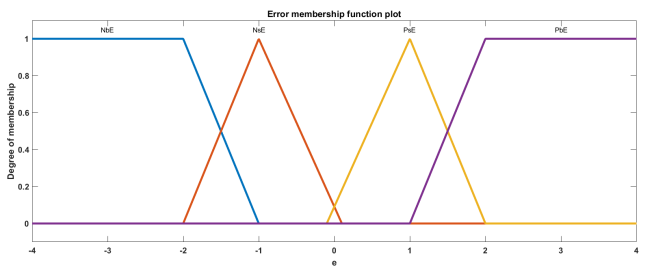
Figure 3. Membership functions of input error (Display range is from -4 to 4).
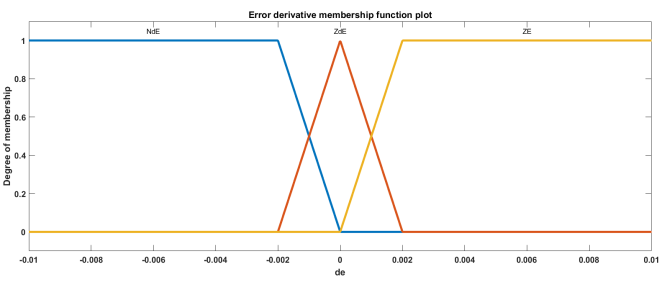
Figure 4. Membership functions of error derivative.
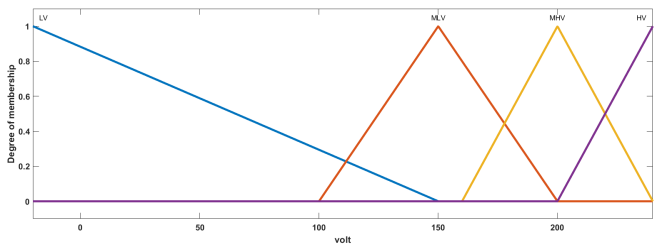
Figure 5. Membership function of consequent.
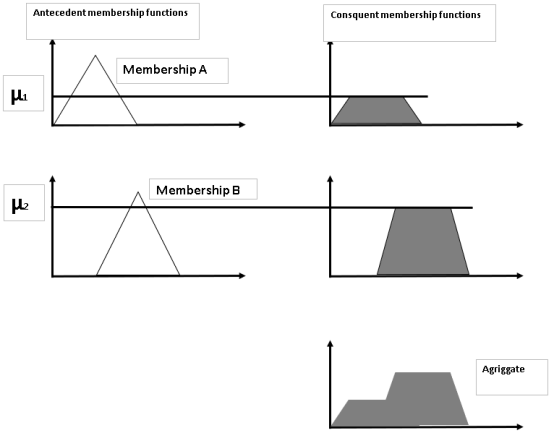
Figure 6. Aggregation in fuzzy inference system.
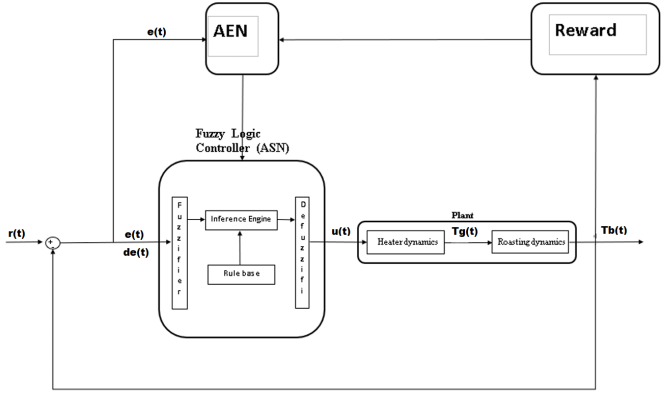
Figure 7. ARIC neuro fuzzy architecture.
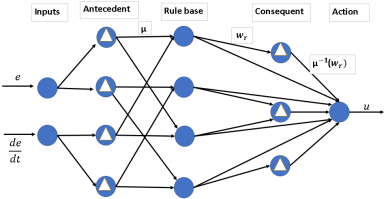
Figure 8. ASN of ARIC neuro fuzzy architecture.
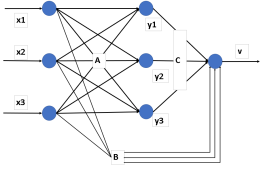
Figure 9. AEN of ARIC neuro fuzzy architecture.
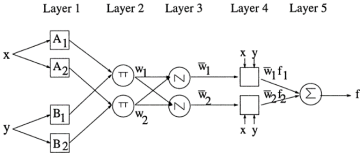
Figure 10. ANFIS controller architecture [8].
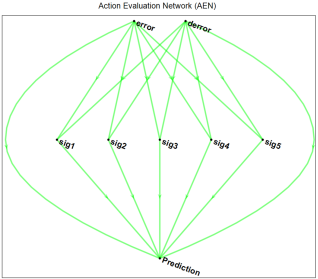
Figure 11. AEN implementation using MATLAB.
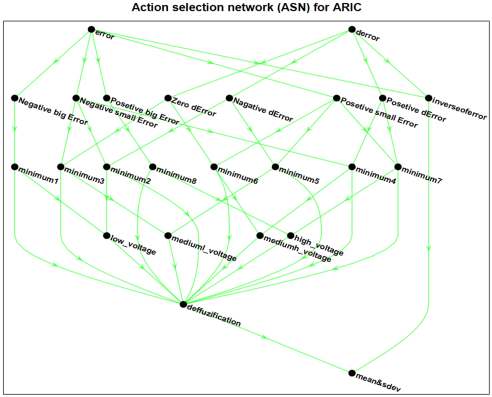
Figure 12. ASN implementation using MATLAB.
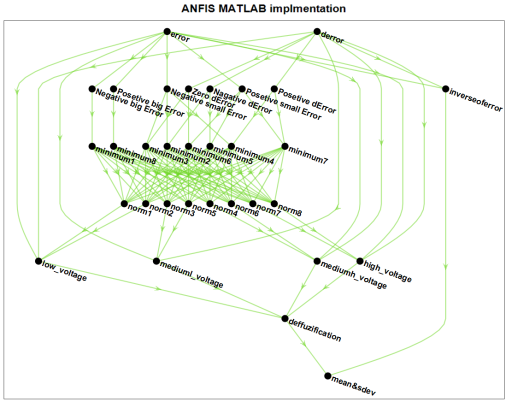
Figure 13. MATLAB implementation of ANFIS.
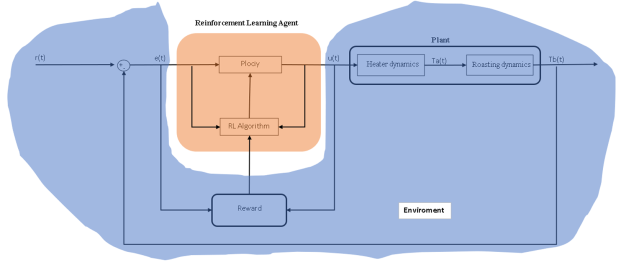
Figure 14. Environment (blue) and Agent (orange).
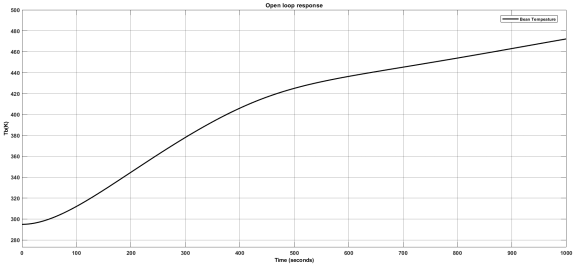
Figure 15. Open loop response of coffee roasting process.
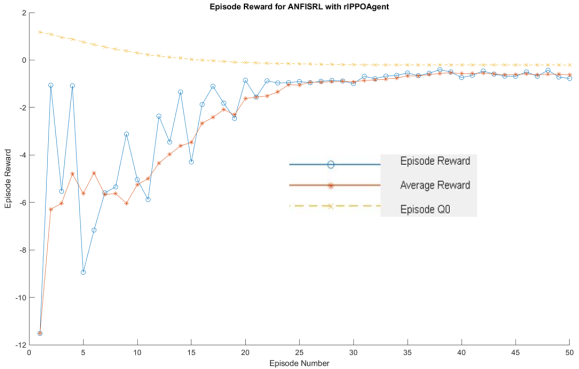
Figure 16. Training Progress of ANFIS neuro fuzzy controller.
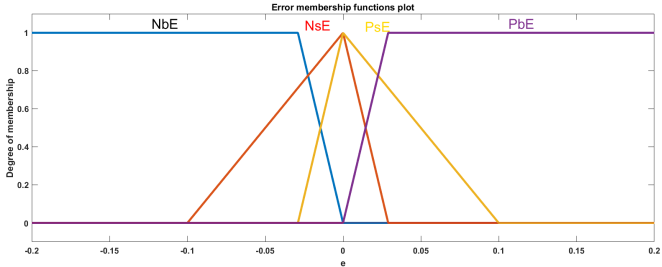
Figure 17. Optimized membership functions plot for error input.
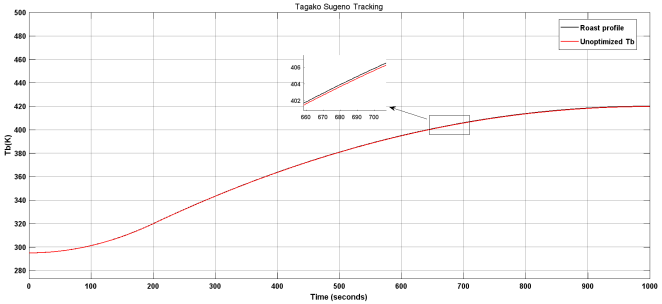
Figure 18. Tracking plot for unoptimized sugeno type controller.
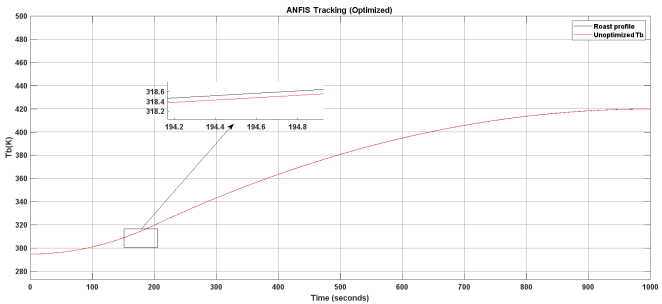
Figure 19. ANFIS neuro fuzzy controller optimized using PPO algorithm.
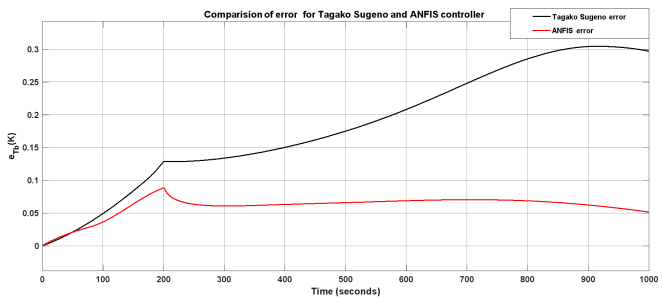
Figure 20. Comparison of Tagako Sugeno and ANFIS controller.
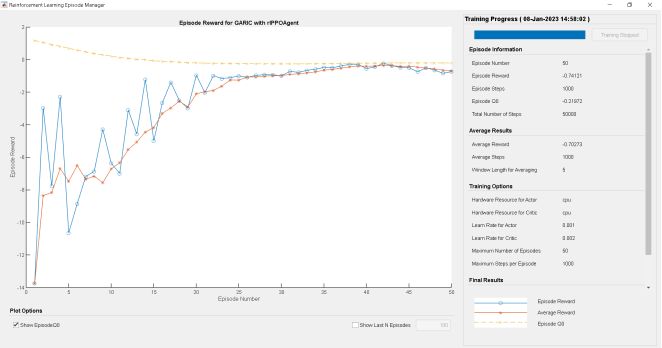
Figure 21. Training progress for ARIC neuro fuzzy architecture.
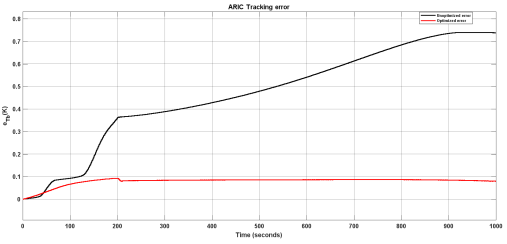
Figure 22. Comparison of error for ARIC unoptimized and optimized controller.
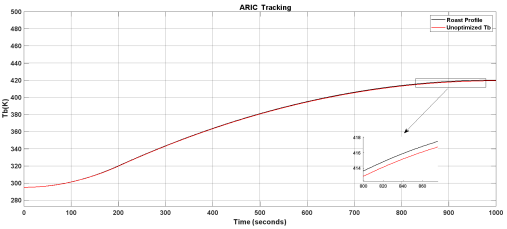
Figure 23. Unoptimized ARIC controller response.
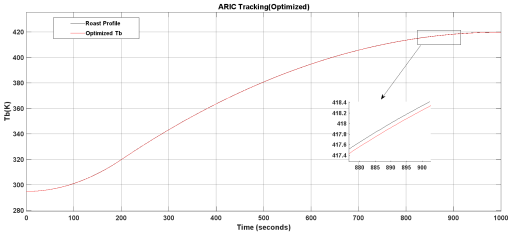
Figure 24. Tracking performance of optimized ARIC controller.
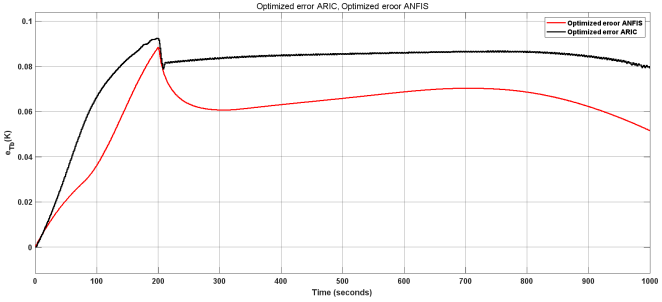
Figure 25. Comparison between ANFIS and ARIC controller.
Information

